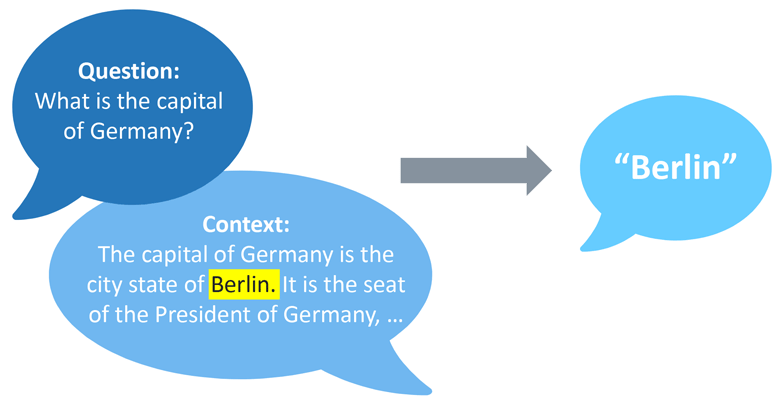
A sneek peak into implementing QuestionAnswering With HuggingFace (inprogress)
huggingface
NLP
fastai
Author
Kurian Benoy
Published
February 27, 2022
from datasets import load_datasetraw_datasets = load_dataset("squad")
Downloading and preparing dataset squad/plain_text (download: 33.51 MiB, generated: 85.63 MiB, post-processed: Unknown size, total: 119.14 MiB) to /root/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453...
Dataset squad downloaded and prepared to /root/.cache/huggingface/datasets/squad/plain_text/1.0.0/d6ec3ceb99ca480ce37cdd35555d6cb2511d223b9150cce08a837ef62ffea453. Subsequent calls will reuse this data.
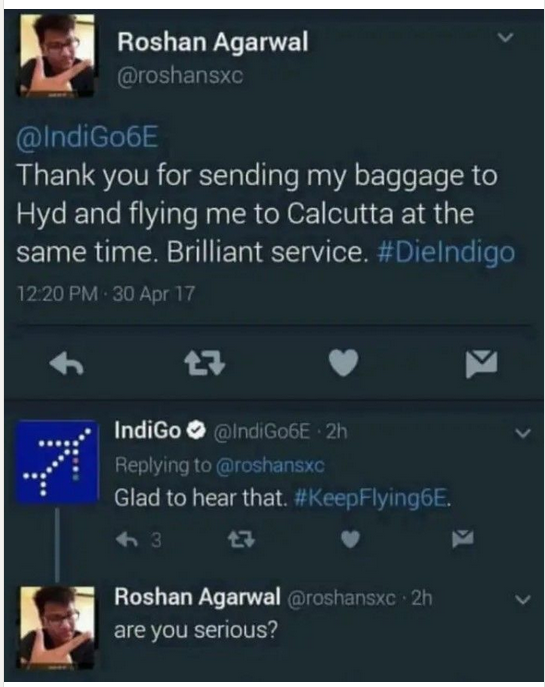
We can see that NLP is hard, and even the best publicly avaiable models performs poorly in this tasks
from transformers import pipelineclassifier = pipeline("sentiment-analysis", model="distilbert-base-uncased")classifier("Thank you for sending my baggage to Hyd and flying me to Calcutta at the same time. Brilliant service.#DieIndigo")
Some weights of the model checkpoint at distilbert-base-uncased were not used when initializing DistilBertForSequenceClassification: ['vocab_layer_norm.bias', 'vocab_projector.weight', 'vocab_projector.bias', 'vocab_transform.bias', 'vocab_layer_norm.weight', 'vocab_transform.weight']
- This IS expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DistilBertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['classifier.bias', 'pre_classifier.weight', 'classifier.weight', 'pre_classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
checkpoint ="cardiffnlp/twitter-roberta-base-sentiment"classifier = pipeline("sentiment-analysis", model=checkpoint)classifier("Thank you for sending my baggage to Hyd and flying me to Calcutta at the same time. Brilliant service.#DieIndigo")
checkpoint ="finiteautomata/bertweet-base-sentiment-analysis"classifier = pipeline("sentiment-analysis", model=checkpoint)classifier("Thank you for sending my baggage to Hyd and flying me to Calcutta at the same time. Brilliant service.#DieIndigo")
emoji is not installed, thus not converting emoticons or emojis into text. Please install emoji: pip3 install emoji
[{'label': 'NEG', 'score': 0.9447618126869202}]
question_answerer = pipeline("question-answering")question_answerer( question="Where do I work?", context="My name is Sylvain and I work at Hugging Face in Brooklyn",)
No model was supplied, defaulted to distilbert-base-cased-distilled-squad (https://huggingface.co/distilbert-base-cased-distilled-squad)
question_answerer = pipeline("question-answering")question_answerer( question="What was feedback?", context="Thank you for sending my baggage to Hyd and flying me to Calcutta at the same time. Brilliant service.#DieIndigo",)
No model was supplied, defaulted to distilbert-base-cased-distilled-squad (https://huggingface.co/distilbert-base-cased-distilled-squad)
For specific question answering - use question answering models
Encoder-only models like BERT tend to be great at extracting answers to factoid questions like “Who invented the Transformer architecture?” but fare poorly when given open-ended questions like “Why is the sky blue?” In these more challenging cases
If you’re interested in this type of generative question answering, we recommend checking out our demo based on the ELI5 dataset. Using Lonformer model.
Context: Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.
Question: To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?
Answer: {'text': ['Saint Bernadette Soubirous'], 'answer_start': [515]}
{'text': ['Denver Broncos', 'Denver Broncos', 'Denver Broncos'], 'answer_start': [177, 177, 177]}
{'text': ['Santa Clara, California', "Levi's Stadium", "Levi's Stadium in the San Francisco Bay Area at Santa Clara, California."], 'answer_start': [403, 355, 355]}
Super Bowl 50 was an American football game to determine the champion of the National Football League (NFL) for the 2015 season. The American Football Conference (AFC) champion Denver Broncos defeated the National Football Conference (NFC) champion Carolina Panthers 24–10 to earn their third Super Bowl title. The game was played on February 7, 2016, at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California. As this was the 50th Super Bowl, the league emphasized the "golden anniversary" with various gold-themed initiatives, as well as temporarily suspending the tradition of naming each Super Bowl game with Roman numerals (under which the game would have been known as "Super Bowl L"), so that the logo could prominently feature the Arabic numerals 50.
Where did Super Bowl 50 take place?
from transformers import AutoTokenizermodel_checkpoint ="bert-base-cased"tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
'[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]'
[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basi [SEP]
[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin [SEP]
[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP] Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 [SEP]
[CLS] To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France? [SEP]. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive ( and in a direct line that connects through 3 statues and the Gold Dome ), is a simple, modern stone statue of Mary. [SEP]
inputs = tokenizer( raw_datasets["train"][2:6]["question"], raw_datasets["train"][2:6]["context"], max_length=100, truncation="only_second", stride=50, return_overflowing_tokens=True, return_offsets_mapping=True,)print(f"The 4 examples gave {len(inputs['input_ids'])} features.")print(f"Here is where each comes from: {inputs['overflow_to_sample_mapping']}.")
The 4 examples gave 19 features.
Here is where each comes from: [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3].
Once we have those token indices, we look at the corresponding offsets, which are tuples of two integers representing the span of characters inside the original context. We can thus detect if the chunk of the context in this feature starts after the answer or ends before the answer begins (in which case the label is (0, 0)). If that’s not the case, we loop to find the first and last token of the answer:
answers = raw_datasets["train"][2:6]["answers"]start_positions = []end_positions = []for i, offset inenumerate(inputs["offset_mapping"]): sample_idx = inputs["overflow_to_sample_mapping"][i] answer = answers[sample_idx] start_char = answer["answer_start"][0] end_char = answer["answer_start"][0] +len(answer["text"][0]) sequence_ids = inputs.sequence_ids(i)# Find the start and end of the context idx =0while sequence_ids[idx] !=1: idx +=1 context_start = idxwhile sequence_ids[idx] ==1: idx +=1 context_end = idx -1# If the answer is not fully inside the context, label is (0, 0)if offset[context_start][0] > end_char or offset[context_end][1] < start_char: start_positions.append(0) end_positions.append(0)else:# Otherwise it's the start and end token positions idx = context_startwhile idx <= context_end and offset[idx][0] <= start_char: idx +=1 start_positions.append(idx -1) idx = context_endwhile idx >= context_start and offset[idx][1] >= end_char: idx -=1 end_positions.append(idx +1)start_positions, end_positions
Theoretical answer: a Marian place of prayer and reflection, decoded example: [CLS] What is the Grotto at Notre Dame? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend " Venite Ad Me Omnes ". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grot [SEP]
max_length =384stride =128def preprocess_training_examples(examples): questions = [q.strip() for q in examples["question"]] inputs = tokenizer( questions, examples["context"], max_length=max_length, truncation="only_second", stride=stride, return_overflowing_tokens=True, return_offsets_mapping=True, padding="max_length", ) offset_mapping = inputs.pop("offset_mapping") sample_map = inputs.pop("overflow_to_sample_mapping") answers = examples["answers"] start_positions = [] end_positions = []for i, offset inenumerate(offset_mapping): sample_idx = sample_map[i] answer = answers[sample_idx] start_char = answer["answer_start"][0] end_char = answer["answer_start"][0] +len(answer["text"][0]) sequence_ids = inputs.sequence_ids(i)# Find the start and end of the context idx =0while sequence_ids[idx] !=1: idx +=1 context_start = idxwhile sequence_ids[idx] ==1: idx +=1 context_end = idx -1# If the answer is not fully inside the context, label is (0, 0)if offset[context_start][0] > end_char or offset[context_end][1] < start_char: start_positions.append(0) end_positions.append(0)else:# Otherwise it's the start and end token positions idx = context_startwhile idx <= context_end and offset[idx][0] <= start_char: idx +=1 start_positions.append(idx -1) idx = context_endwhile idx >= context_start and offset[idx][1] >= end_char: idx -=1 end_positions.append(idx +1) inputs["start_positions"] = start_positions inputs["end_positions"] = end_positionsreturn inputs
‘Theoretical answer: a Marian place of prayer and reflection, decoded example: [CLS] What is the Grotto at Notre Dame? [SEP] Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend ” Venite Ad Me Omnes “. Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grot [SEP]’
Indeed, we don’t see the answer inside the context.
✏️ Your turn! When using the XLNet architecture, padding is applied on the left and the question and context are switched. Adapt all the code we just saw to the XLNet architecture (and add padding=True). Be aware that the [CLS] token may not be at the 0 position with padding applied.
Now that we have seen step by step how to preprocess our training data, we can group it in a function we will apply on the whole training dataset. We’ll pad every feature to the maximum length we set, as most of the contexts will be long (and the corresponding samples will be split into several features), so there is no real benefit to applying dynamic padding here:
def preprocess_validation_examples(examples): questions = [q.strip() for q in examples["question"]] inputs = tokenizer( questions, examples["context"], max_length=max_length, truncation="only_second", stride=stride, return_overflowing_tokens=True, return_offsets_mapping=True, padding="max_length", ) sample_map = inputs.pop("overflow_to_sample_mapping") example_ids = []for i inrange(len(inputs["input_ids"])): sample_idx = sample_map[i] example_ids.append(examples["id"][sample_idx]) sequence_ids = inputs.sequence_ids(i) offset = inputs["offset_mapping"][i] inputs["offset_mapping"][i] = [ o if sequence_ids[k] ==1elseNonefor k, o inenumerate(offset) ] inputs["example_id"] = example_idsreturn inputs
import numpy as npn_best =20max_answer_length =30predicted_answers = []for example in small_eval_set: example_id = example["id"] context = example["context"] answers = []for feature_index in example_to_features[example_id]: start_logit = start_logits[feature_index] end_logit = end_logits[feature_index] offsets = eval_set["offset_mapping"][feature_index] start_indexes = np.argsort(start_logit)[-1 : -n_best -1 : -1].tolist() end_indexes = np.argsort(end_logit)[-1 : -n_best -1 : -1].tolist()for start_index in start_indexes:for end_index in end_indexes:# Skip answers that are not fully in the contextif offsets[start_index] isNoneor offsets[end_index] isNone:continue# Skip answers with a length that is either < 0 or > max_answer_length.if ( end_index < start_indexor end_index - start_index +1> max_answer_length ):continue answers.append( {"text": context[ offsets[start_index][0] : offsets[end_index][1] ],"logit_score": start_logit[start_index] + end_logit[end_index], } ) best_answer =max(answers, key=lambda x: x["logit_score"]) predicted_answers.append({"id": example_id, "prediction_text": best_answer["text"]})
from datasets import load_metricmetric = load_metric("squad")
metric
Metric(name: "squad", features: {'predictions': {'id': Value(dtype='string', id=None), 'prediction_text': Value(dtype='string', id=None)}, 'references': {'id': Value(dtype='string', id=None), 'answers': Sequence(feature={'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int32', id=None)}, length=-1, id=None)}}, usage: """
Computes SQuAD scores (F1 and EM).
Args:
predictions: List of question-answers dictionaries with the following key-values:
- 'id': id of the question-answer pair as given in the references (see below)
- 'prediction_text': the text of the answer
references: List of question-answers dictionaries with the following key-values:
- 'id': id of the question-answer pair (see above),
- 'answers': a Dict in the SQuAD dataset format
{
'text': list of possible texts for the answer, as a list of strings
'answer_start': list of start positions for the answer, as a list of ints
}
Note that answer_start values are not taken into account to compute the metric.
Returns:
'exact_match': Exact match (the normalized answer exactly match the gold answer)
'f1': The F-score of predicted tokens versus the gold answer
Examples:
>>> predictions = [{'prediction_text': '1976', 'id': '56e10a3be3433e1400422b22'}]
>>> references = [{'answers': {'answer_start': [97], 'text': ['1976']}, 'id': '56e10a3be3433e1400422b22'}]
>>> squad_metric = datasets.load_metric("squad")
>>> results = squad_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'exact_match': 100.0, 'f1': 100.0}
""", stored examples: 0)
theoretical_answers = [ {"id": ex["id"], "answers": ex["answers"]} for ex in small_eval_set]print(predicted_answers[0])print(theoretical_answers[0])
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForQuestionAnswering: ['cls.predictions.transform.LayerNorm.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight']
- This IS expected if you are initializing BertForQuestionAnswering from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForQuestionAnswering from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForQuestionAnswering were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['qa_outputs.bias', 'qa_outputs.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
from huggingface_hub import notebook_loginnotebook_login()
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
! sudo apt install git-lfs! git-lfs install
Reading package lists... Done
Building dependency tree
Reading state information... Done
git-lfs is already the newest version (2.3.4-1).
The following package was automatically installed and is no longer required:
libnvidia-common-470
Use 'sudo apt autoremove' to remove it.
0 upgraded, 0 newly installed, 0 to remove and 39 not upgraded.
Error: Failed to call git rev-parse --git-dir --show-toplevel: "fatal: not a git repository (or any of the parent directories): .git\n"
Git LFS initialized.
PyTorch: setting up devices
The default value for the training argument `--report_to` will change in v5 (from all installed integrations to none). In v5, you will need to use `--report_to all` to get the same behavior as now. You should start updating your code and make this info disappear :-).
/content/bert-finetuned-squad is already a clone of https://huggingface.co/kurianbenoy/bert-finetuned-squad. Make sure you pull the latest changes with `repo.git_pull()`.
Using amp half precision backend
/usr/local/lib/python3.7/dist-packages/transformers/optimization.py:309: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use thePyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
FutureWarning,
***** Running training *****
Num examples = 88729
Num Epochs = 1
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 11092