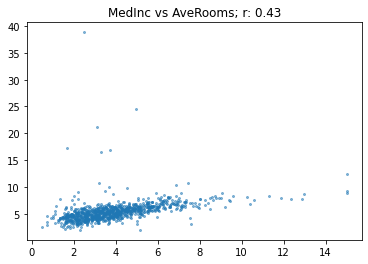
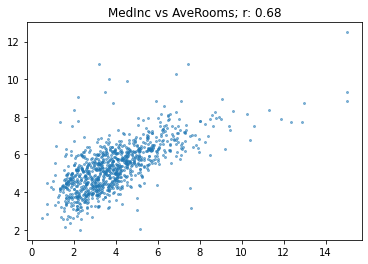
array([[ 1. , -0.12, 0.43, -0.08, 0.01, -0.07, -0.12, 0.04, 0.68],
[-0.12, 1. , -0.17, -0.06, -0.31, 0. , 0.03, -0.13, 0.12],
[ 0.43, -0.17, 1. , 0.76, -0.09, -0.07, 0.12, -0.03, 0.21],
[-0.08, -0.06, 0.76, 1. , -0.08, -0.07, 0.09, 0. , -0.04],
[ 0.01, -0.31, -0.09, -0.08, 1. , 0.16, -0.15, 0.13, 0. ],
[-0.07, 0. , -0.07, -0.07, 0.16, 1. , -0.16, 0.17, -0.27],
[-0.12, 0.03, 0.12, 0.09, -0.15, -0.16, 1. , -0.93, -0.16],
[ 0.04, -0.13, -0.03, 0. , 0.13, 0.17, -0.93, 1. , -0.03],
[ 0.68, 0.12, 0.21, -0.04, 0. , -0.27, -0.16, -0.03, 1. ]])