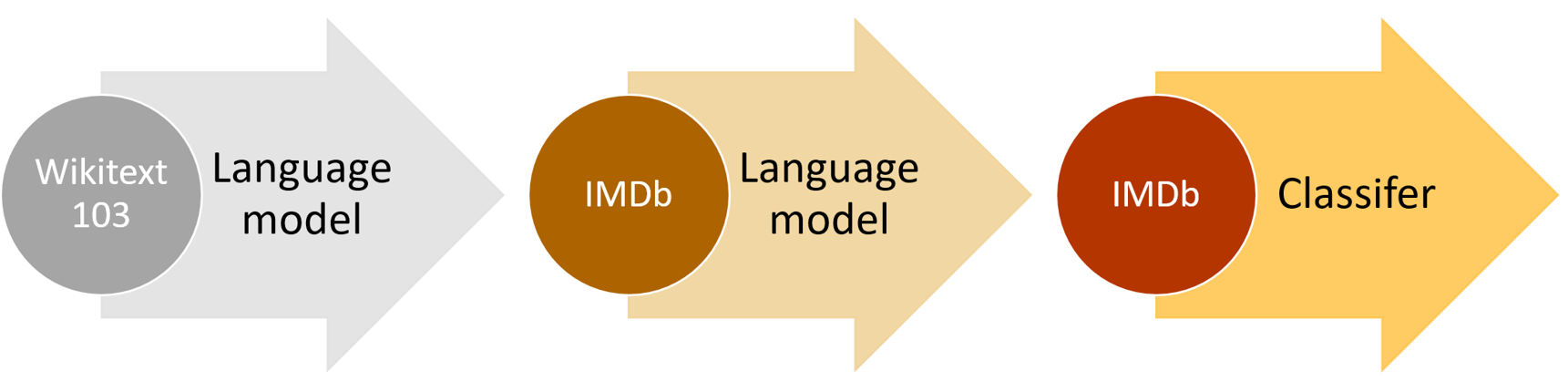
Given a pre-trained model, which is a large model which is trained on a very specific task. If we want to fit it into our specific dataset we will train and use the pre-trained model to build a new model which works very well for our task.
Picture from fast.lesson covering steps in finetuning a text classifier model
Fine tuning is still relevant
Why try fine-tuning in Whisper?
In your problem, the open source Whisper model doesn’t give good results.
HuggingFace Team conducted a whisper fine tuning event for 2 weeks from 5th December 2022 to 19th December 2022. The results were out on 23rd December 2022.
The goal was to to fine-tune the Whisper model to build state-of-the-art speech recognition systems in the languages of our choice 🗣
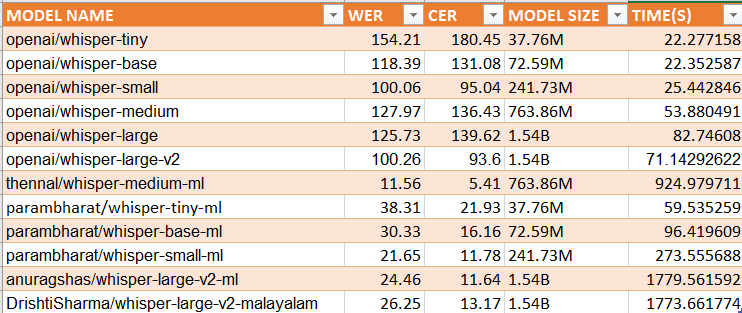
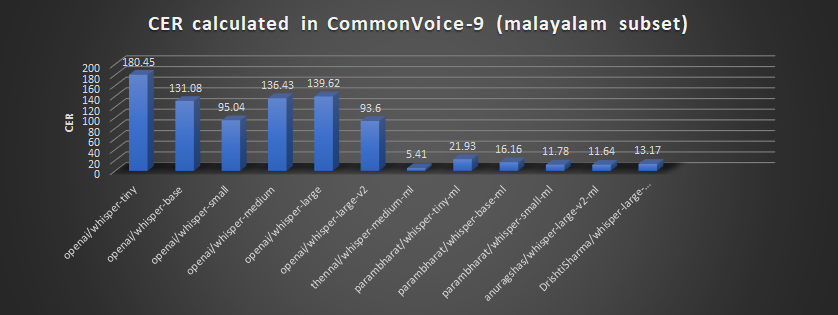
Malayalam models in Whisper Event
For the language Malayalam, the results are as follows:
Malayalam models performance in whisper event according to leaderboard
Winning models in Malayalam in Whisper Event
The winning model for Common voice: thennal/whisper-medium-ml
The winning model for Fleurs: parambharath/whisper-small-ml
I was not convinced
I was sceptical about the winning models becuase of:
Achieving 10% WER in Malayalam is astonishing.
In Malayalam there is not even a single yard stick to compare. Most of previous works were done in proprietary datasets and not open-sourced.