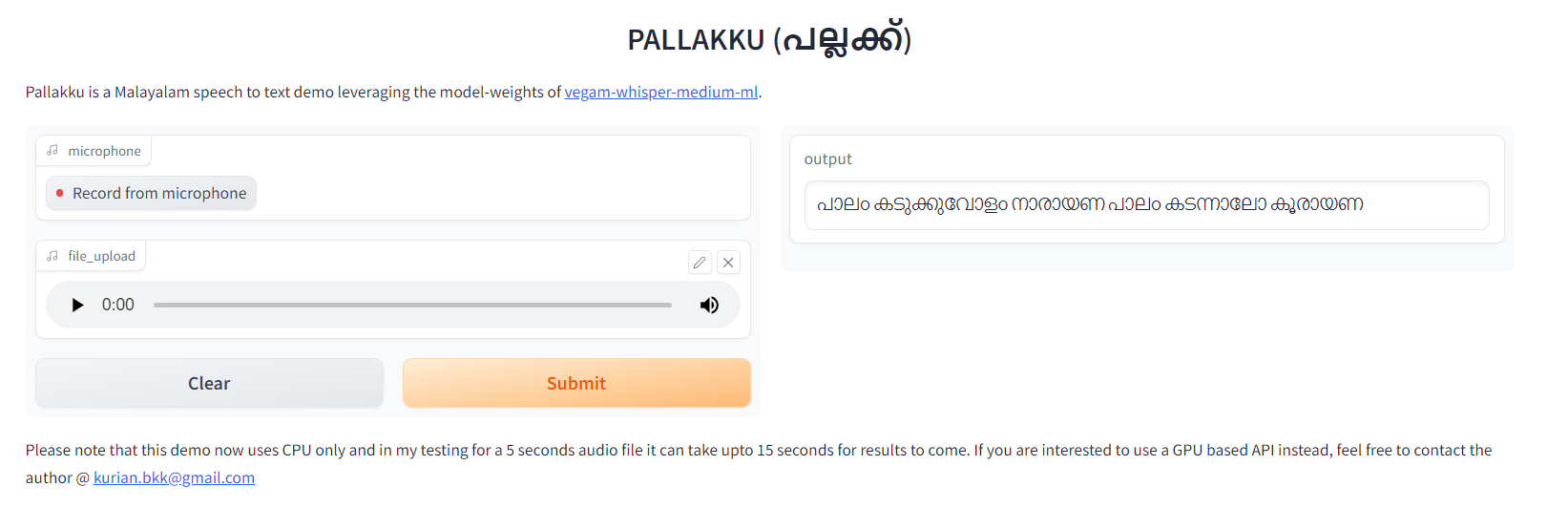
Vegam Whisper Family of Models and demoing Malayalam Speech to Text
Summit 2023 @ Indian Institute of Information Technology, Kottayam (IIIT-K)
Saturday, June 10, 2023
What really matters!
Inspired by
faster-whisper is a reimplementation of OpenAI’s Whisper model using CTranslate2, which is a fast inference engine for Transformer models.
This implementation is up to 4 times faster than openai/whisper for the same accuracy while using less memory. The efficiency can be further improved with 8-bit quantization on both CPU and GPU.
CTranslate2
An awesome library for optimizing ML models for production.
CTranslate2 is a C++ and Python library for efficient inference with Transformer models.
The project implements a custom runtime that applies many performance optimization techniques such as weights quantization, layers fusion, batch reordering, etc., to accelerate and reduce the memory usage of Transformer models on CPU and GPU.
CTranslate2 Whisper converter
It had this utility for converting any whisper based model to faster-whisper like models.